
您需要先安装一个用户脚本管理器扩展,如 Tampermonkey、Greasemonkey 或 Violentmonkey 后才能安装该脚本。
您需要先安装一个用户脚本管理器扩展,如 Tampermonkey 或 Violentmonkey 后才能安装该脚本。
您需要先安装一个用户脚本管理器扩展,如 Tampermonkey 或 Violentmonkey 后才能安装该脚本。
您需要先安装一个用户脚本管理器扩展,如 Tampermonkey 或 Userscripts 后才能安装该脚本。
您需要先安装一款用户脚本管理器扩展(如 Tampermonkey)后才能安装此脚本。
您需要先安装一个用户脚本管理器扩展后才能安装该脚本。




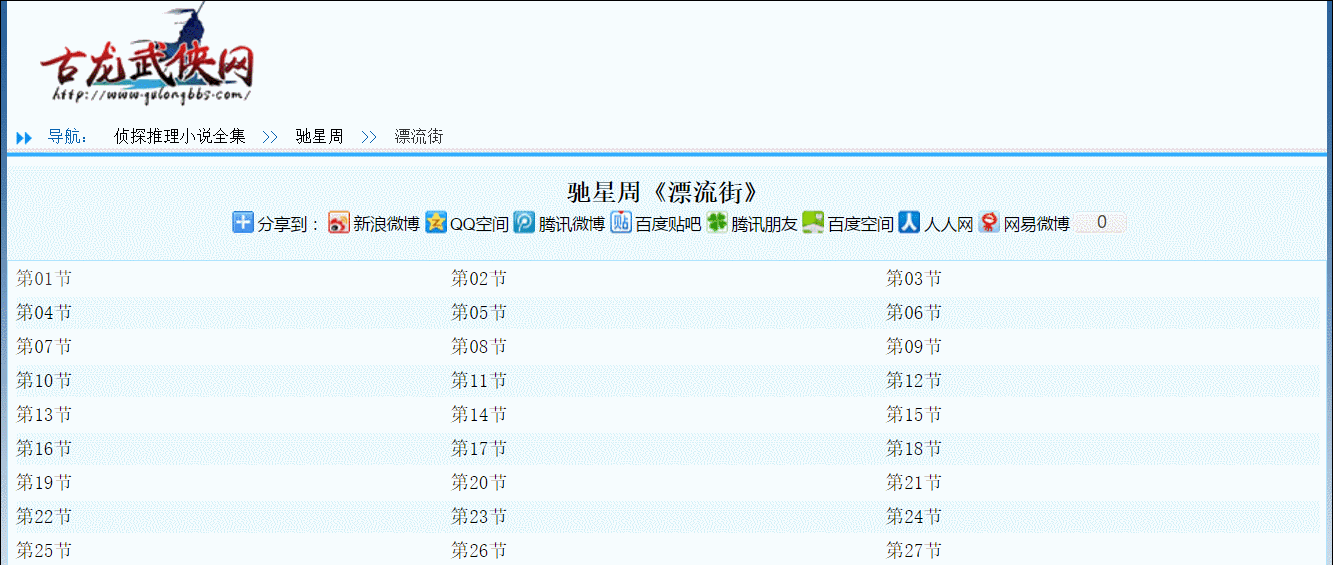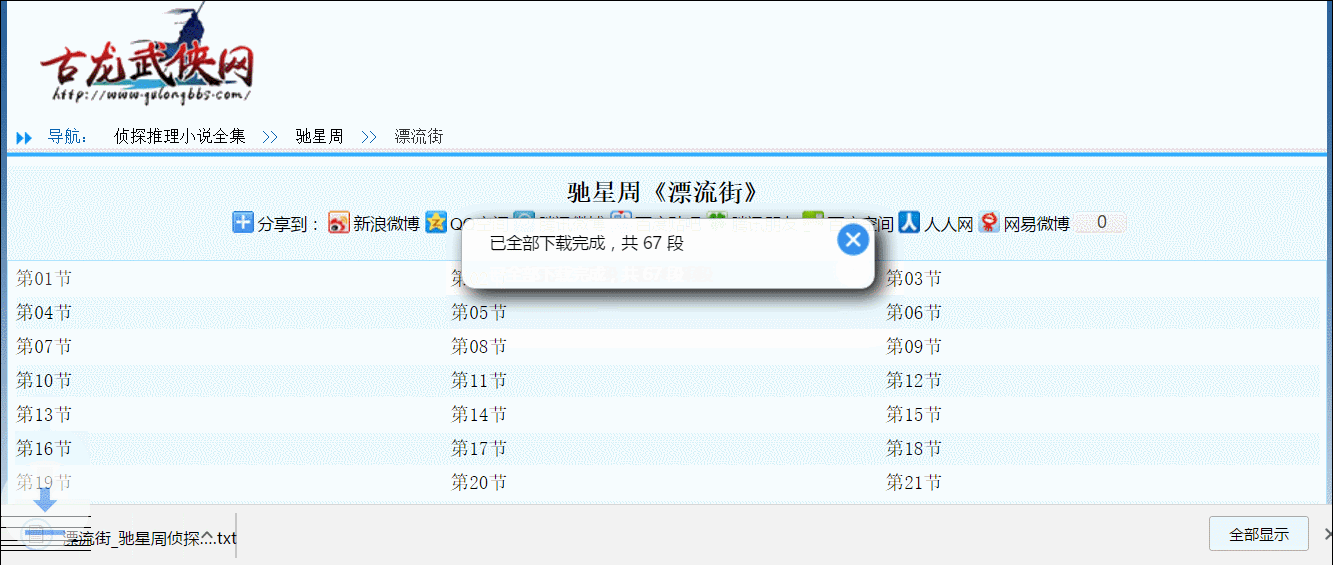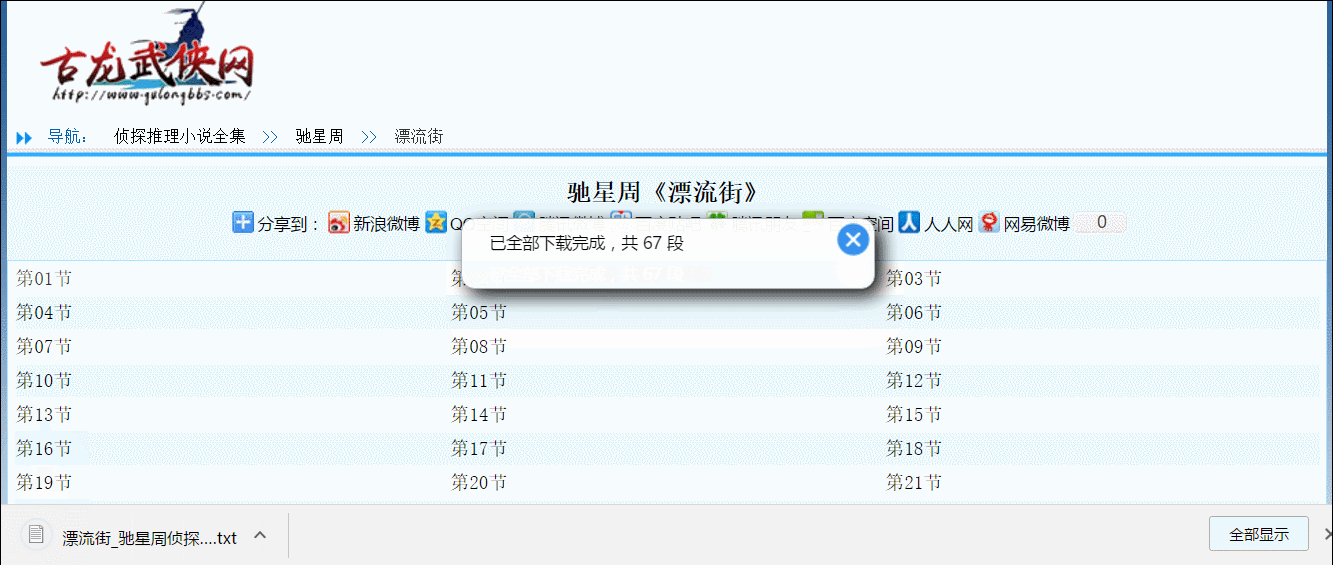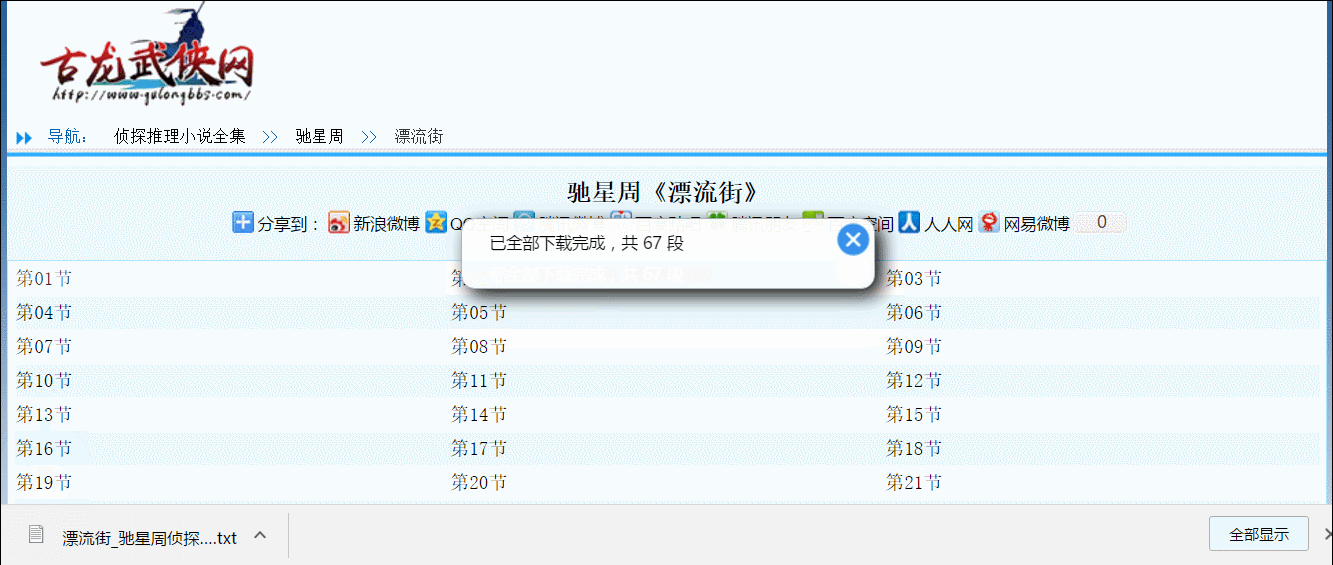


 因为我要下载驰星周的漂流街,却发现前人的轮子“【小说】下载脚本”不能用,又不想为这破站 dogedoge 写规则,而且
因为我要下载驰星周的漂流街,却发现前人的轮子“【小说】下载脚本”不能用,又不想为这破站 dogedoge 写规则,而且